Datanode only do saving block data.
The manipulation data stored in ${hadoop.tmp.dir}/dfs/name/current
The file fsimage is storing core values for Namenode, we call it name table which is so important.
Because it assembled all pieces of data blocks into one file. It can only access by one process a time.
And a file named "${hadoop.tmp.dir}/dfs/name/in_use.lock" means this manipulation is locked by one process(Namenode)
So if a Namenode trying to start, it needs to check the lock first, if there is no lock, it can start.
For name table redundancy, we can set dfs.name.dir with multiple values, separate by comma, no white space accepted. We can use nfs to store name table to multiple servers.
${hadoop.tmp.dir}/dfs/name/current/edits: Transaction file.
Can also use comma-delimited for redundancy.
SecondaryNameNode
Since NameNode is busy for user requests, SecondaryNameNode take the position to commit the data operations.
SecondaryNameNode downloads fsimage and edits from Namenode, then combine them together and generate new fsimage. Save it locally, then also send new fsimage to NameNode, let NameNode to reset edits.
SecondaryNameNode default installed on NameNode, but should be separate from NameNode, move it to other server.
As we say, SecondaryNameNode acts like a backup of fsimage for NameNode, but some un-committed data will not stay in SecondaryNameNode. So if we use fsimage from SecondaryNameNode, it may not be up-to-date totally because there are some un-commited data not saved in fsimage yet. So SecondaryNameNode is a cold backup.
DataNode
block: unit of data. Default 67108864K = 64M (can change by dfs.block.size)
Every time DataNode will write at least one block, however, in HDFS, a file will not occupy the whole block of space. So this is good to hard drive disk usage.

File name ending with ".meta" means it's a verification file for one data block.
Version file:
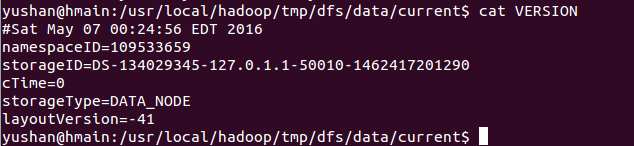
dfs.replication is configured how many replication to have
No comments:
Post a Comment