Sunday, April 15, 2018
Saturday, October 22, 2016
HBase Application

API Available
Java API: Full-featured, does not require server daemon, just need client libraries/configs to be installed
REST API: Easy to use, stateless, but slower than Java API, require REST API server, can directly get data from http request
Thrift API: Multi-language support, light weight, require Thrift API server
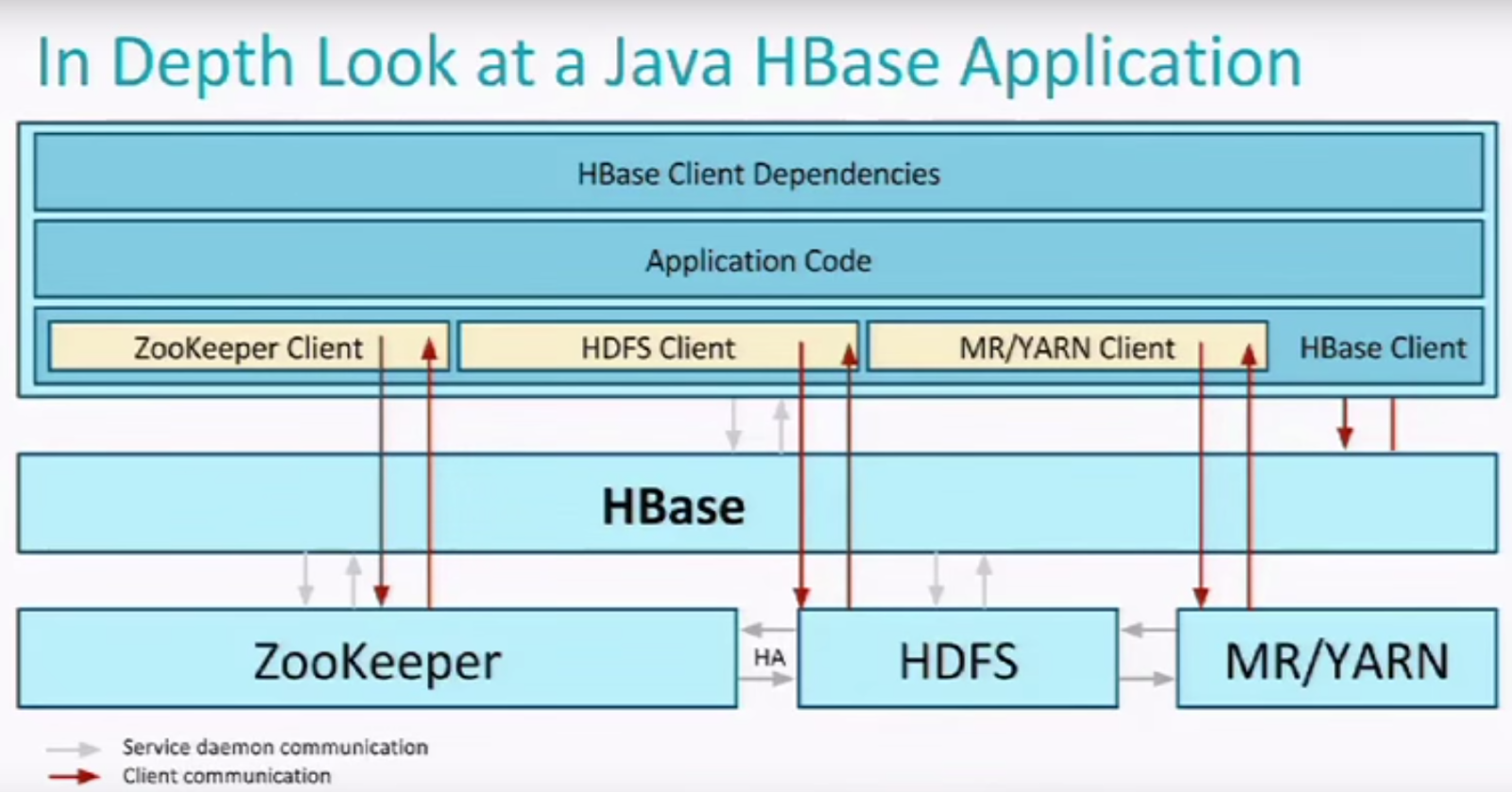
Configuration
- Key-values that define client application properties
DDL
- HBase Admin
create/modify/delete tables - H*Descriptor
Describe and manipulate metadata
DML
- Mutations: Incr/Delete/Put/Check-and-Put/Multiput*
Query
- Scan/Get/Filter
HBase System Architecture, Compare to Others

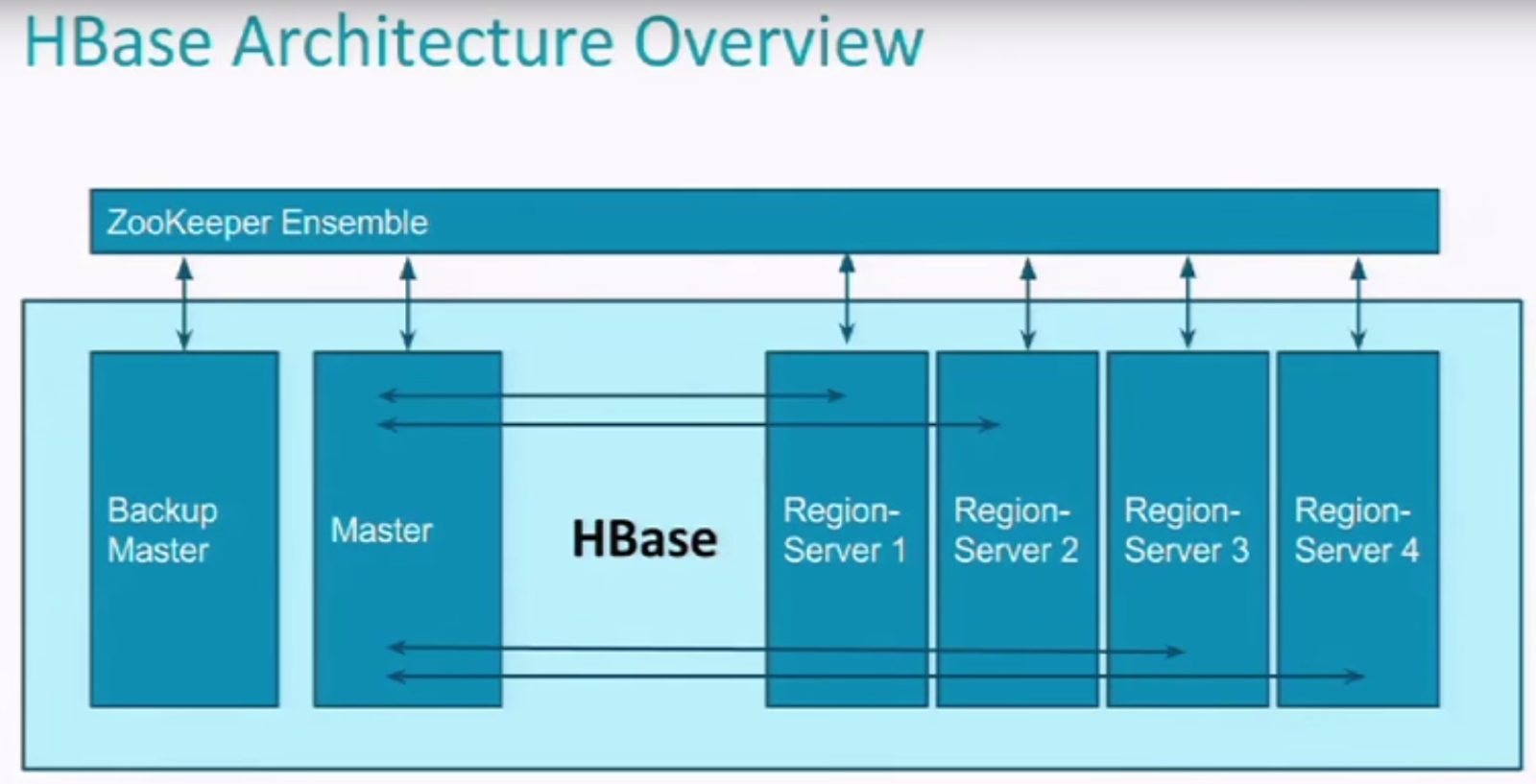
.META. 's Region Server will be well known by ZooKeeper,
So Master Node can know where to read it by talking to ZooKeeper.
Once .META. is cached, Master can find any data lives in HBase

HBase VS Other NoSQL
- Great large Scalibility
- Strict Consistency
- Availability not perfect, but can be managed
- Integrates with Hadoop
Very efficient bulk loads and MapReduce analysis - Ordered range partitions(not Hash)
- Automatically shards/scales(just add more servers)
- Sparse storage(for each row)
Compare to RDBMS

Enterprise Hadoop Cluster Architecture
Enterprise Hadoop Cluster Architecture
Master: SPOF to one single node
Master: SPOF to one single node
- NameNode, JobTracker / ResourceManager
- Hive Metastore, HiveServer2
- Impala StateStore, Catalog Server
- Spark Master
Node kernel environment setup
- Ulimit, /etc/security/limits.conf to configure nofile
Since default Linux system only allow 1024 sessions for file system.
For Hadoop Cluster, Habase, this is not enough, so we need to configure this. - THP(Transparent Huge Page), ACPI, Memory overcommit issue
THP: A new function from Linux kernel, its cache may not compatible with Hadoop, this will cause high memory, so it's better to turn it off.
ACPI: Power management, this may also cause high memory, better to turn off.
Memory Overcommit: System don't give more memory to app when app has a lot commit(50% total), so we need to either configure it higher or turn it off. - Customize configuration on different functional node
If High Memery? How to configure swap?
High disk IO? Then we may not need high OverCommit.
High CPU, high system load?
Enterprise Hadoop Cluster Data Management
HDFS config
- HDFS Block Size: dfs.block.size
- Replication Factor: dfs.replication, default is 3
- Turn on dfs.permissions? fs.permissions.umask-mode
- User permission
- DataNode's dfs disk partition, better to be separate from Linux system partition, otherwise may cause system fail to start because of disk space.
Resource Allocation
- CPU, Memory, Disk IO, Network IO
- HDFS, MapReduce(Yarn), Hive jobs
- HBase, Hive, Impala, Spark resource allocation, limitations
Enterprise Hadoop Cluster Task Scheduling
Oozie
- dispatch HDFS, MapReduce jobs, Pig, Hive, Sqoop, Java Apps, shell, email
- take advantage of cluster resources
- an alternative of cron job
Distribution start job
Parallel start multiple jobs
Can fail tolerance, re-try, alarm in working flow
ZooKeeper
- Synchronize node situation
- The communication between HBase's master server and region server
- Synchronize region's situation for HBase's tables
online or split?
Hadoop Cluster Monitors
Cloudera Manager's Monitor Tool
- Strong, Full of Monitor values, Monitors well to Impala
- Waste of system resources
Ganglia
- Monitor by collecting Hadoop Metrics
- Use self's gmond to collect CPU, Memory, NetworkIO
- Collect JMX, IPC, RPC data
- Weak point: No disk IO by default
Graphite
- Good third party plugins, can push KPI in java applications(StatsD, Yammer Metrics)
- Can collect server data using plugins(collectd, logster, jmxtrans)
Splunk: expensive
Nagios, Icinga
Hadoop Cluster Issue and Limitation
Issues
- HA: Too many too many single nodes
- Dangerous to upgrade
- Waste too much memory
Limitations
- Missing solutions for cross data center
- High concurrent bottle neck
- Impala, Spark no ability to handle too many query at the same time, and no solution yet
- No matter which type of model, database. Join is a big issue
Spark is still not good for this, it's more like MapReduce + Pig
HBase Table and Storage Design
HBase is a set of tables defined by Key-Values
Definitions:


Special Table
Table .META.
This table is using the same format as regular tables.
It can be in any one node of HBase cluster, it stores information for where to find the target region.
Definitions:
- Row KeyEach row has a unique Row Key
- Column FamilyUse to group different columns, defined when building the table
- Column QualifierIdentify each column, can be added in run-time
Expandable, may have different numbers of Qualifiers in each row - timestampA cell can have different versions of data based on different timestamps(for consistency)
A Row is referred by a Row Key
So a Column is referred by a Column Family and a Column Qualifier
A Cell is referred by a Row and a Column
A Cell will contain multiple version of values based on different timestamps
The above four things combines together to become a Key in the following format:
[Row Key]/[Column Family]:[Column Qualifier]/[timestamp]
With this Key, we can find the unique value we want to read.
Every value we get will be in byte[] format, developer need to know the structure of value themselves.
Rows are strongly consistency.

How does HBase db stores in file system?
- Group continues rows into the same Region
- Region is divided by each Column Family to be several units
- Each one of these divided unit stored as a single file in file system
- The values in each file are in lexicographical order(I think order by Column Qualifier)
So if we open one HBase db file, it will only have
- Continues rows
- Values in the same Column Family
- (I think)Values are ordered by Column Qualifier

Special Table
Table .META.
This table is using the same format as regular tables.
It can be in any one node of HBase cluster, it stores information for where to find the target region.
Friday, August 12, 2016
TransferQueue
If someone is already waiting to take the element, we don't need to put it in the queue, just directly transfer it to receiver.
Java 7 introduced the TransferQueue. This is essentially a BlockingQueue with an
additional operation—transfer(). This operation will immediately transfer a work
item to a receiver thread if one is waiting. Otherwise it will block until there is a thread
available to take the item. This can be thought of as the “recorded delivery” option—
the thread that was processing the item won’t begin processing another item until it
has handed off the current item. This allows the system to regulate the speed at which
the upstream thread pool takes on new work.
It would also be possible to regulate this by using a blocking queue of bounded
size, but the TransferQueue has a more flexible interface. In addition, your code may
show a performance benefit by replacing a BlockingQueue with a TransferQueue.
This is because the TransferQueue implementation has been written to take into
account modern compiler and processor features and can operate with great efficiency.
As with all discussions of performance, however, you must measure and prove
benefits and not simply assume them. You should also be aware that Java 7 ships with
only one implementation of TransferQueue—the linked version.
In the next code example, we’ll look at how easy it is to drop in a TransferQueue as
a replacement for a BlockingQueue. Just these simple changes to listing 4.13 will
upgrade it to a TransferQueue implementation, as you can see here.
Java 7 introduced the TransferQueue. This is essentially a BlockingQueue with an
additional operation—transfer(). This operation will immediately transfer a work
item to a receiver thread if one is waiting. Otherwise it will block until there is a thread
available to take the item. This can be thought of as the “recorded delivery” option—
the thread that was processing the item won’t begin processing another item until it
has handed off the current item. This allows the system to regulate the speed at which
the upstream thread pool takes on new work.
It would also be possible to regulate this by using a blocking queue of bounded
size, but the TransferQueue has a more flexible interface. In addition, your code may
show a performance benefit by replacing a BlockingQueue with a TransferQueue.
This is because the TransferQueue implementation has been written to take into
account modern compiler and processor features and can operate with great efficiency.
As with all discussions of performance, however, you must measure and prove
benefits and not simply assume them. You should also be aware that Java 7 ships with
only one implementation of TransferQueue—the linked version.
In the next code example, we’ll look at how easy it is to drop in a TransferQueue as
a replacement for a BlockingQueue. Just these simple changes to listing 4.13 will
upgrade it to a TransferQueue implementation, as you can see here.
public class BlockingQueueTest1 {
public static void main(String[] args) {
final Update.Builder ub = new Update.Builder();
final TransferQueue<Update> lbq = new LinkedTransferQueue<Update>();
MicroBlogExampleThread t1 = new MicroBlogExampleThread(lbq, 10) {
public void doAction() {
text = text + "X";
Update u = ub.author(new Author("Tallulah")).updateText(text)
.build();
boolean handed = false;
try {
handed = updates.tryTransfer(u, 100, TimeUnit.MILLISECONDS);//tryTransfer
} catch (InterruptedException e) {
}
if (!handed)
System.out.println("Unable to hand off Update to Queue due to timeout");
else System.out.println("Offered");
}
};
MicroBlogExampleThread t2 = new MicroBlogExampleThread(lbq, 200) {
public void doAction() {
Update u = null;
try {
u = updates.take();
System.out.println("Took");
} catch (InterruptedException e) {
return;
}
}
};
t1.start();
t2.start();
}
}
abstract class MicroBlogExampleThread extends Thread {
protected final TransferQueue<Update> updates;
protected String text = "";
protected final int pauseTime;
private boolean shutdown = false;
public MicroBlogExampleThread(TransferQueue<Update> lbq_, int pause_) {
updates = lbq_;
pauseTime = pause_;
}
public synchronized void shutdown() {
shutdown = true;
}
@Override
public void run() {
while (!shutdown) {
doAction();
try {
Thread.sleep(pauseTime);
} catch (InterruptedException e) {
shutdown = true;
}
}
}
public abstract void doAction();
}
Fine-Grained Control of BlockingQueue
We have learned BlockingQueue
http://gvace.blogspot.com/2016/08/blockingqueue.html
In addition to the simple take() and offer() API, BlockingQueue offers another way
to interact with the queue that provides even more control, at the cost of a bit of
extra complexity. This is the possibility of putting or taking with a timeout, to allow
the thread encountering issues to back out from its interaction with the queue and do something else instead.
Followed a TransferQueue which is a little more efficient.
http://gvace.blogspot.com/2016/08/transferqueue.html
http://gvace.blogspot.com/2016/08/blockingqueue.html
In addition to the simple take() and offer() API, BlockingQueue offers another way
to interact with the queue that provides even more control, at the cost of a bit of
extra complexity. This is the possibility of putting or taking with a timeout, to allow
the thread encountering issues to back out from its interaction with the queue and do something else instead.
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.LinkedBlockingQueue;
import java.util.concurrent.TimeUnit;
public class BlockingQueueTest1 {
public static void main(String[] args) {
final Update.Builder ub = new Update.Builder();
final BlockingQueue<Update> lbq = new LinkedBlockingQueue<>(100);
MicroBlogExampleThread t1 = new MicroBlogExampleThread(lbq, 10) {
public void doAction() {
text = text + "X";
Update u = ub.author(new Author("Tallulah")).updateText(text)
.build();
boolean handed = false;
try {
handed = updates.offer(u, 100, TimeUnit.MILLISECONDS);//set timeout
} catch (InterruptedException e) {
}
if (!handed)
System.out.println("Unable to hand off Update to Queue due to timeout");
else System.out.println("Offered");
}
};
MicroBlogExampleThread t2 = new MicroBlogExampleThread(lbq, 1000) {
public void doAction() {
Update u = null;
try {
u = updates.take();
System.out.println("Took");
} catch (InterruptedException e) {
return;
}
}
};
t1.start();
t2.start();
}
}
abstract class MicroBlogExampleThread extends Thread {
protected final BlockingQueue<Update> updates;
protected String text = "";
protected final int pauseTime;
private boolean shutdown = false;
public MicroBlogExampleThread(BlockingQueue<Update> lbq_, int pause_) {
updates = lbq_;
pauseTime = pause_;
}
public synchronized void shutdown() {
shutdown = true;
}
@Override
public void run() {
while (!shutdown) {
doAction();
try {
Thread.sleep(pauseTime);
} catch (InterruptedException e) {
shutdown = true;
}
}
}
public abstract void doAction();
}
Followed a TransferQueue which is a little more efficient.
http://gvace.blogspot.com/2016/08/transferqueue.html
Subscribe to:
Comments (Atom)