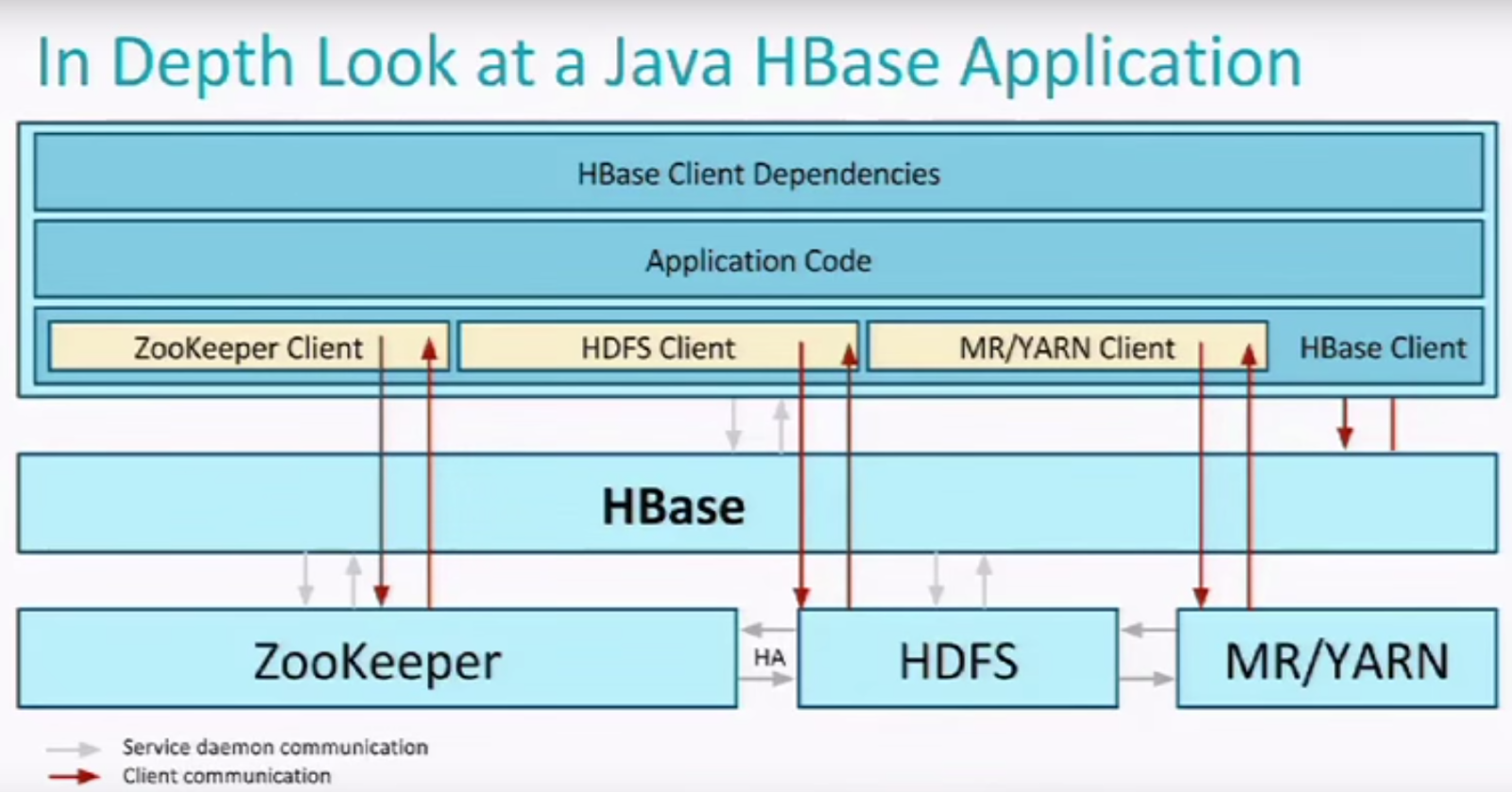
API Available
Java API: Full-featured, does not require server daemon, just need client libraries/configs to be installed
REST API: Easy to use, stateless, but slower than Java API, require REST API server, can directly get data from http request
Thrift API: Multi-language support, light weight, require Thrift API server
Configuration
- Key-values that define client application properties
DDL
- HBase Admin
create/modify/delete tables - H*Descriptor
Describe and manipulate metadata
DML
- Mutations: Incr/Delete/Put/Check-and-Put/Multiput*
Query
- Scan/Get/Filter